AI will Change Security Video Analytics – Fact or Fiction?
Author – Dr Rob Dupre PhD – Product Manager VCA Technology
Overview of AI in security
In recent years, Artificial Intelligence (AI) has been the buzzword in the video analytics domain. Trade show stands are rife with AI demos promoting ambitious functionality set to change the face of CCTV in security. Impressive as many of these demonstrations are, there is a definite air of scepticism on the part of the end-user. Is the hype around AI warranted, and can science actually deliver? This feels reminiscent of a decade ago when video analytics promised to revolutionise CCTV monitoring. Today, reliable and effective analytics is the mainstream and is driving tangible business value.
That said, there is no denying that the last five years of AI innovation has led to tangible and practical solutions, with the security industry finally starting to reap the benefits. However, AI is now at a precipice – on the cusp of what industry experts call an “AI winter” – so, everyone is wondering what’s next and what is possible. This paper investigates precisely this, focusing on the physical security space.
What is AI?
One formal definition of Artificial Intelligence (AI) identifies the technology with the “development of computer systems able to perform tasks normally requiring human intelligence, such as visual perception, speech recognition, decision-making, and translation between languages.” [1]
In reality, the term AI covers a wide range of applications and tends to refer to the current problem being tackled, which of course is constantly evolving. When we think of AI in the security industry, this usually translates to a few key areas:
- Asset protection & monitoring
- Access control
- Business intelligence
- Decision support
Machine learning is the process of teaching a system to perform a task, while Deep Learning is just a subset of Machine Learning. There are many other non-Deep Learning based ML methods which, for the purposes of this paper, will be referred to as traditional ML approaches.Often, when AI is mentioned, what is really being referenced is the Machine Learning (ML) or Deep Learning (DL) algorithm powering that solution. For example, license plate recognition (LPR) is often the application of a DL model to locate and extract a license plate from an image, coupled with ML algorithms cross-referencing information from a database. Therefore, this application should be referred to as a combination of ML and DL – not simply AI.
The distinction between traditional ML and DL is an important one, as the recent boom in AI solutions often refers to advances in Deep Learning techniques. In the majority of cases, the use of Deep Learning has led to a significant jump in accuracy over traditional ML techniques. For example, a well known academic image classification challenge, in which images must be classified into one of a thousand different classes, has seen a notable increase in accuracy – going from 50% of the images being classified correctly in 2011, using traditional ML techniques, to nearly 90% today using modern DL techniques. The figure below illustrates the improvement in the ImageNet challenge over time [2].
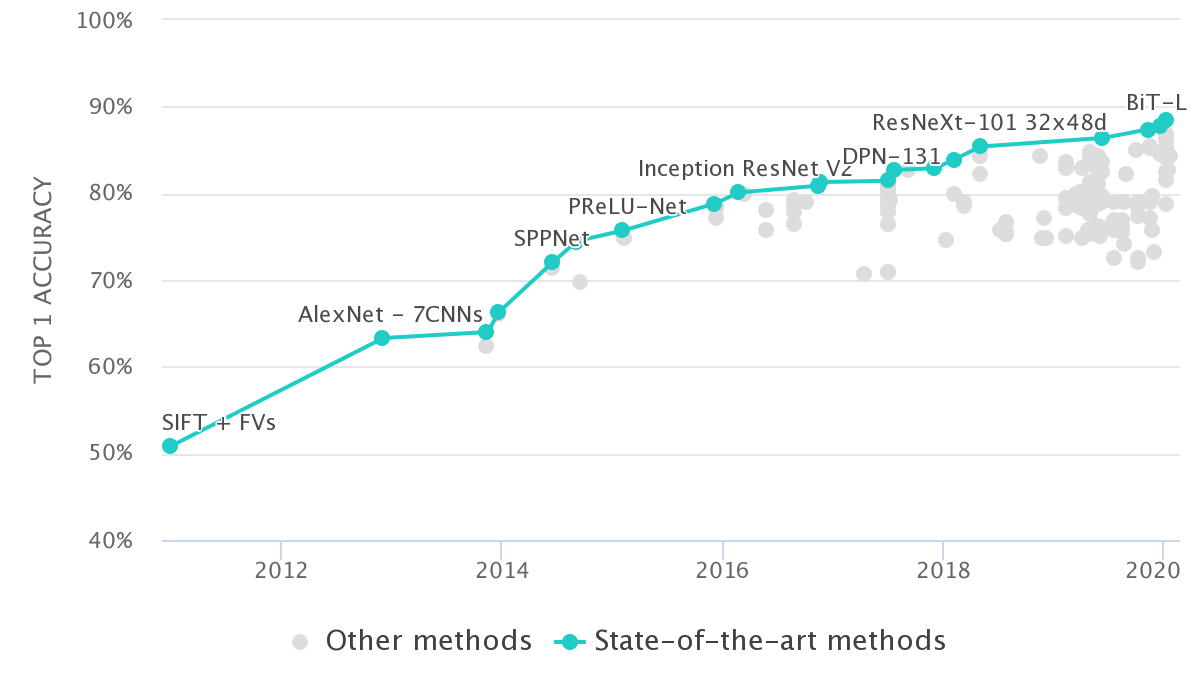
Machine Learning vs Deep Learning
To understand Deep Learning’s dramatic improvement over traditional Machine Learning techniques, let’s look at how an example asset protection use case could be approached with both methodologies. The goal is to detect if the object in the field of view of a particular camera represents a threat and should generate an alarm (person, vehicle, etc), or constitutes mere background noise that can be ignored. To begin, through the use of a movement-based tracker (another ML system) a camera has detected motion and defined a region of interest around the object.

Machine Learning (ML)
The traditional Machine Learning pipeline generally requires the developer to represent an input (e.g. a region of interest in an image) into a structured feature descriptor of that input: for example, a set of numbers that represents the shape in the image (HOG, SIFT), or possibly another property in the image (colour, texture, etc.).
The model is then trained by feeding labelled examples of the object feature descriptors you want to recognise (person, vehicle) and object feature descriptors of objects you expect to see but want to ignore (trees, shadows, animals etc.). The Machine Learning algorithm learns to group these feature descriptors into these categories so, when a new unlabelled feature representation is fed to the system, it can make an assessment as to which category it might fall into.
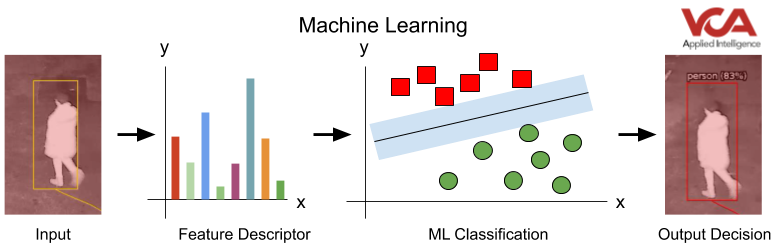
A system’s accuracy hinges on a developers’ ability to come up with a feature descriptor which the Machine Learning algorithm can easily group into classes to detect vs those to ignore. One of the biggest advantages of using human-designed feature descriptors is the data required to train the ML model is reduced. Creation of labelled datasets to train any Machine Learning algorithm takes significant time and therefore resource. As a consequence, traditional Machine Learning techniques are still very much relevant due to this significant time and cost-saving.
Deep Learning (DL)
Deep Learning follows a similar process. However, instead of relying on a human-in-the-loop method of developing a robust feature descriptor, the Deep Learning system itself just looks at the labelled input data to learn the best way of grouping the images. By showing the system large numbers of samples (training), the system refines its model to best describe the data it is being shown. The disadvantage is that, for a Deep Learning model to learn that best representation from the data, a notably larger amount of data is necessary.
However, although the data requirements are more significant, the Deep Learning approach removes the guesswork of a developer trying to define the optimal representation of an input to enable the system to learn. It also has the advantage that the same approach can be applicable to a range of different problems, whereas traditional ML may require redesigning the feature descriptor based on the application.
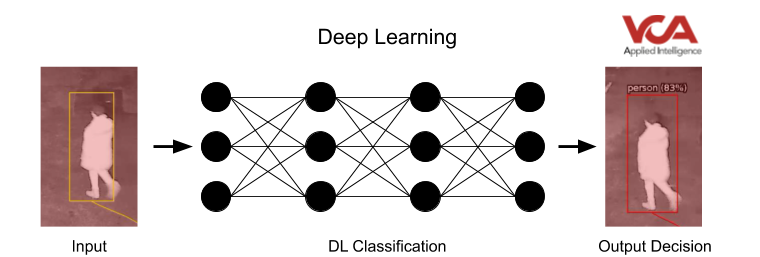
Deep Learning has demonstrated its advantages over traditional methods. However, the real question is how it can be used to improve business processes or increase precision in detection, while reducing costs for security businesses. The race to contain costs whilst enhancing accuracy is where the biggest industry pain points are found. Typically, the deployment of Deep Learning backend systems in the field of CCTV analytics demands much more powerful and specialised hardware. Despite this, Deep Learning algorithms are starting to appear in the field and their benefits felt.
Example Algorithms for use in Security Applications
VCA Technology has been assessing algorithms based on customer feedback and ongoing projects. By exploring their applications, sample use cases, as well as requirements for implementation and deployment, the benefit of ML and DL, can be analysed.
Detection and Classification
Detection and classification algorithms combine the localisation and identification of an object in a single step, negating the need to use other algorithms to detect movement first. The image below represents the output of such an algorithm. In this instance, a bounding box outlining a detected object, a classification (person, car, etc.) and confidence in the algorithm’s decision (between 0 and 1). This analysis is done on a single frame, meaning the algorithm has no knowledge of where the object has been, or if a detected object was seen in a previous frame. Without this knowledge, simply knowing if a detected object is even moving is not possible, meaning stationary objects are detected. Additionally, rules such as dwell and direction analysis are also not possible without a motion detection and/or object tracking algorithm to provide this information.

Some common models are Faster R-CNN [3], Single Shot Detector (SSD) [4] and You Only Look Once (YOLOv3 seen above) [5]. Performance varies based on a number of parameters but around 15-20fps using an NVIDIA Titan X is possible. Minified versions of these models are also being developed.
GPU Hardware cost per channel: £250-350
Pros
- Off-the-shelf localisation and classification
- Able to support a large number of classes (>100)
- Mature models improve accuracy, model size and therefore deployment costs are always coming down
Cons
- Static objects are also detected
- Requires tracking components for common applications in the security industry
Object Classification
Object classification is the process of categorising an area of interest into one of a number of predefined classes (person, vehicle, etc). This approach means you only need to make use of the algorithm when something of interest has been detected, e.g. movement in a zone. This facilitates the sharing of a single GPU resource between many channels. For example, VCA Technology’s Deep Learning Filter (DLF) model for detecting people and types of vehicles can classify around 34 objects per second on a NVidia GTX1080 (~£400). In a perimeter detection environment, this single GPU resource could be utilised across as many as 64 channels.

In the example above, moving objects have been tracked by VCA Technology’s motion tracking engine and bounding boxes have been defined. These regions of interest are then analysed by the Deep Learning Filter (DLF) to provide a classification (person, vehicle, etc.) and the level of confidence in the algorithm’s decision (between 0% and 100%). As with all motion detection engines, we can see objects created as a result of illumination changes from the car’s headlights. However, these objects are classified as background by the DLF and are ignored. Furthermore, the vehicle is classified and an event generated (red bounding box). Objects outside the defined red zone are also ignored and never sent to the Deep Learning Filter, saving GPU resources.
GPU Hardware cost per channel: less than £10
Pros
- Very low cost per channel
- Able to support multiple classes
- Integrates with existing tracking technologies
- Mature models improve accuracy
Cons
- Requires object detection component to provide inputs to the model
Pose Estimation
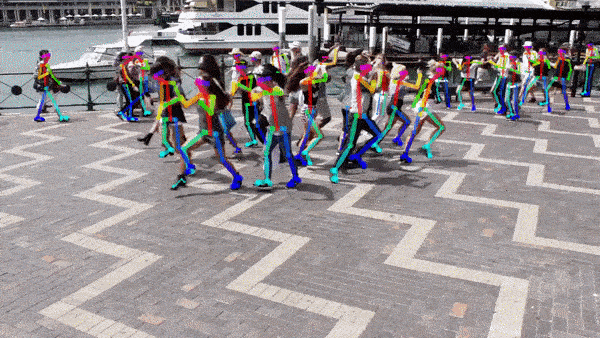
Pose estimation algorithms allow the detection and localisation of body parts such as the shoulders, elbows and ankles from an input image. This information in isolation is not that informative, but can be used as the basis for systems which detect if someone has fallen over (Slip-trip-and-fall), or even behaviour analysis systems for fight detection. However, the computation cost is high, with the current state of the art methods (OpenPose [6]) runs at 4fps using a Nvidia GTX 1080ti.
GPU Hardware cost per channel: £500-700
Pros
- Complex behaviours can be detected, covering both security and safety
- Mature models improve accuracy
- Active area of research, will bring cost per channel down
Cons
- Cost prohibitive
- Comprehensive work required to utilise the algorithm outputs into a fully-fledged system
Without a doubt, the developments in both accuracy and application for AI and its subsets over the last few years are astounding. A number of factors have contributed to this. The fact that AI was, until recently, a relatively new field of research means innovation is fast. The development of optimised hardware (parallel processing devices e.g. GPUs) enables the research, while edge-based processing devices enable cost-effective deployment of the solutions.
However, it is likely that this initial trend in fast-paced evolution will slow down in the coming years, and the huge progress in precision witnessed recently will give way to more incremental improvements over time. This is by no means a bad thing – on the contrary, it will help establish and refine the technology in a more controlled manner, allowing typically slow-moving industries and legislations to catch up with the technology.
Summary
The barrier to entry for deploying AI solutions and the financial practicality of the applications has been assisted by the continued reduction in component costs – in particular, processing. However, the cost of processing still remains rather high, and the performance expectations driven by TV, films and overzealous salespeople are simply not achievable in a competitive and cost-effective manner.
VCA Technology has always held efficient hardware requirements as a central tenet to its development programme, and continues to strive for the best performance at the best price. Potential users of Deep Learning-based video analytics need to ensure that their expectations of system performance are tempered by reality. Educating the industry on AI, Video Content Analytics (VCA) and Deep Learning accurately and comprehensively are crucial to setting more achievable expectations of these tools. Manufacturers and vendors in this market sector have a responsibility to ensure the products and performance are understood, not overhyped and oversold. All organisations involved in the sales and promotion of AI-based products should contribute to creating realistic expectations of this technology, or they risk negatively impacting the reputation not just of their company but of the security industry as a whole.
AI is here to stay, and its benefits for the security industry are clear. It will be an exciting few years and we look forward to facing and overcoming the challenges ahead.
Key Takeaways
- Artificial Intelligence (AI) is the general term for current advances in visual perception, speech recognition, decision-making and translation between languages
- Machine Learning (ML) refers to the algorithms that drive AI systems
- Deep Learning (DL) is a subset of machine learning which has been the driving force behind the significant jump in performance across a range of applications
- Deep learning algorithms are now mature enough to see widespread deployment in the security industry and are helping to improve accuracy and reduce costs
- The fast innovation of AI algorithms over the last few years will now give way to more incremental improvements
- Hardware requirements for the deployment of deep learning at the edge are helping to get algorithms out in the wild and making a positive impact in the security industry